In last year’s Facebook F8 conference, Sachin Kulkarni, who worked on Facebook’s Video Infrastructure, gave a talk (watch it here) to introduce the design of Facebook’s Streaming Video Engine System (SVE). I found this talk particularly interesting because it revealed, in a very well structured, concise yet informative way, how Facebook infrastructure team came up with a solution to build a video system solving user frustrations by reviewing the end-to-end process, and how such a design meet the goal of being fast, flexible, scalable, and efficient. After watching the presentation video for a few times, I thought it would be helpful to write down some notes here, for my own reviewing in the future, and for people who might be interested in Facebook’s media infrastructure.
Sharing on Facebook started from largely text, and quickly changed to be largely photos. Since 2014, more videos started to be posted and shared among users. The challenge was, building a video processing system is much harder than building a text or image processing system. Videos are greedy, they will consume all your resources: CPU, memory, disk, network, and anything else.
Before building the Streaming Video Engine system, the team started by reviewing Facebook’s existing video uploading and processing process, which was slow and not scalable. They found several problems need change or improvement:
- No unified clients
- Several disk reads and writes in the critical path
- Was doing serial processing throughout
- Read a video as one single big file, instead of splitting it up to chunks
The new Streaming Video Engine (SVE) is expected to solve the aforementioned problems, and to meet the four design goals:
- Fast: make users upload their videos super fast
- Flexible: usable for different Facebook products
- Scalable: everything at Facebook has to scale
- Efficient: storage efficiency, processing efficiency, and more importantly consume less bytes of users’ data plan
These four design goals, in my opinion, are also the most common goals applicable to most engineering infrastructure systems.
Let’s take a deep dive to see how SVE was designed to meet these goals.
Fast
- First step is build a common library (for video uploading) that could be used for the clients cross platforms (Web, Mobile, Android, etc.). With the common library, optimizations on video uploading can be applied to all platforms.
- The uploading library has functions to split a video by GOP (Group of Pictures, a GOP roughly is a scene in the video) alignment. So any given video can be split to segments, which can have multiple GOPs.
- Uploading process starts as soon as the clients split a video into segaments. The client uploads one segment a time to the web server.
- Web server sends out segments to the preprocessor, which is a write-through cache.
- Proprocessor handles:
- Normalize the video (segment) if it needs to
- Notify the scheduler that there are video segments available to be encoded
- Write the video (segment) to the original storage
- Further split the video segment into GOPs
- Scheduler will find workers to encode videos. Multiple works can be utilized and each worker will process one or multiple GOPs.
- Overlapped upload and encoding process: While proprocessor, scheduler and works are working, the uploading process is still ongoing. Clients continues splitting videos into segments and uploading to the web server.
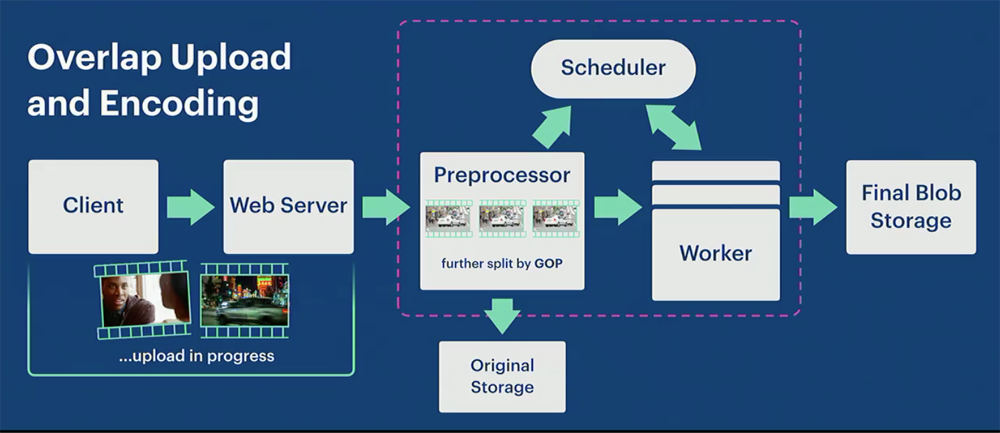
With this design, the process speedup reached 2.3x (small videos < 3MB) ~ 9.3x (large videos > 1G).
Flexible
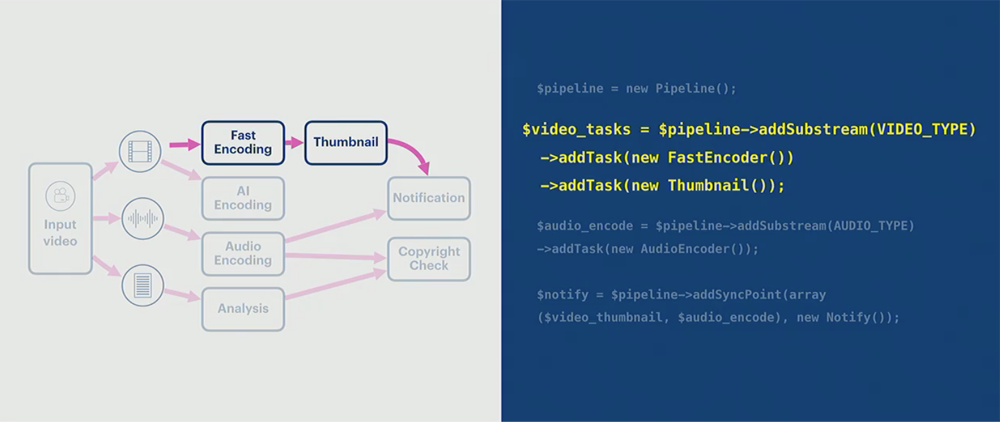
- The key insight that allows SVE to be flexible is, all the video processing pipelines can be represented as a DAG (Directed Acyclic Graph).
- Arbitrary dependencies can be added between the tasks in the video processing pipepline. The added tasks can be executed in parallel while the main pipeline tasks are running.
- SVE provides very simple API functions for the video pipeline (Ideally, you can add a video processing pipeline in your product in less than 10 lines of code).
Scalable
- SVE was designed to prepare for overloads, such as handling the worldwide uploading “spike” on New Year’s Eve (could be 3x video uploads).
- Building a scalable system is relevant only when the system is robust. When the system gets overloaded, it must gracefully degrade. It cannot crash and burn.
- Prepare for overload along two dimensions: at the pipeline level, and the task level.
- Pipeline level, when uploads overwhelm the system:
- Do not cache original videos in upload: Preprocessor stops caching original videos. Workers then need fetch videos from the original storage, not from preprocessor. The cost here is disk latency is added to the critical path.
- Delay pipeline generation for incoming video. Distinguish the critical video pipeline requests and the non-critical ones, then delay the non-critical ones.
- Reroute traffic to a different (less busy) region (Asia, Europe, US west, etc.)
- Task level (the tasks executed by workers in the pipeline), when too many tasks are running:
- Push back non latency-sensitive jobs
- Turn off A/B tests, which try to figure out the best encoding for the given video
- Add more workers (this requires making it easy to add capacity to SVE)
Efficient
- The high level problem statement here is: If we could use 100% CPU, how can we make the encoded video as small as possible?
- Find the optimal encoding settings to get the best balance between encoded video file size and time spent on encoding. The difficult part is modern encoders can have hundreds of settings for one video. Chance of picking optimal combination is extremely low.
- The adopted solution is:
- Categorize each scene such as “minimal motion”, “rapid movement”, and “complex crowded scene”.
- Build a Neural Network Model and a large training data set to train the network.
- In SVE, video scene segments are sent to a Fingerprint generator, which generates fingerprints and sends them to the Neural Network Model.
- The neural network figures out optimal encoding settings (could be multiple) for each scene, and sends the encoding settings to encoders.
- the encoder takes the settings, and encodes the video scenes in multiple ways. Then discard the encoded videos which are below quality bar.
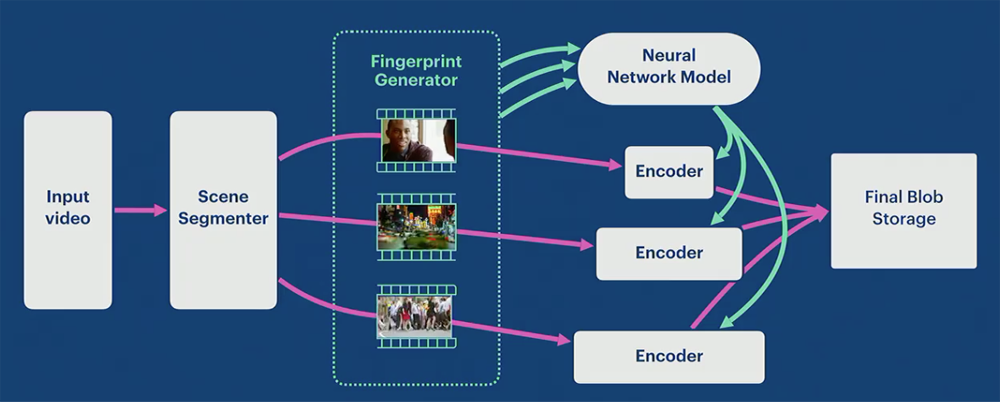
SVE achieved 20% smaller video file sizes. This is a huge saving of user’s data plans.
This Streaming Video Engine was designed, coded and tested in roughly 9 months. The most important learnings are:
- E2E view: To find an optimal solution, we need look at the flow end to end
- Multi-dimensional flexibility is a key for making the system most useful
- Parallel and shadow mode testing to find correctness and scalability issues before production
- Design the ability to handle extreme products such as 360 videos
- Track direct measures (latency, reliability, etc.) and indirect measures (number of videos uploaded, watch times, etc.). Mapping indirect measures to direct measures could give you a good view in figuring out what you could do better next.